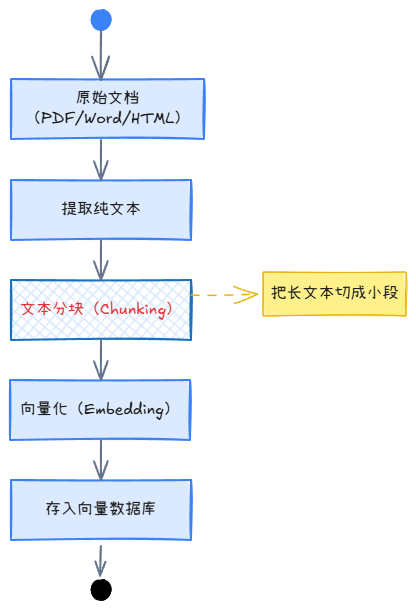
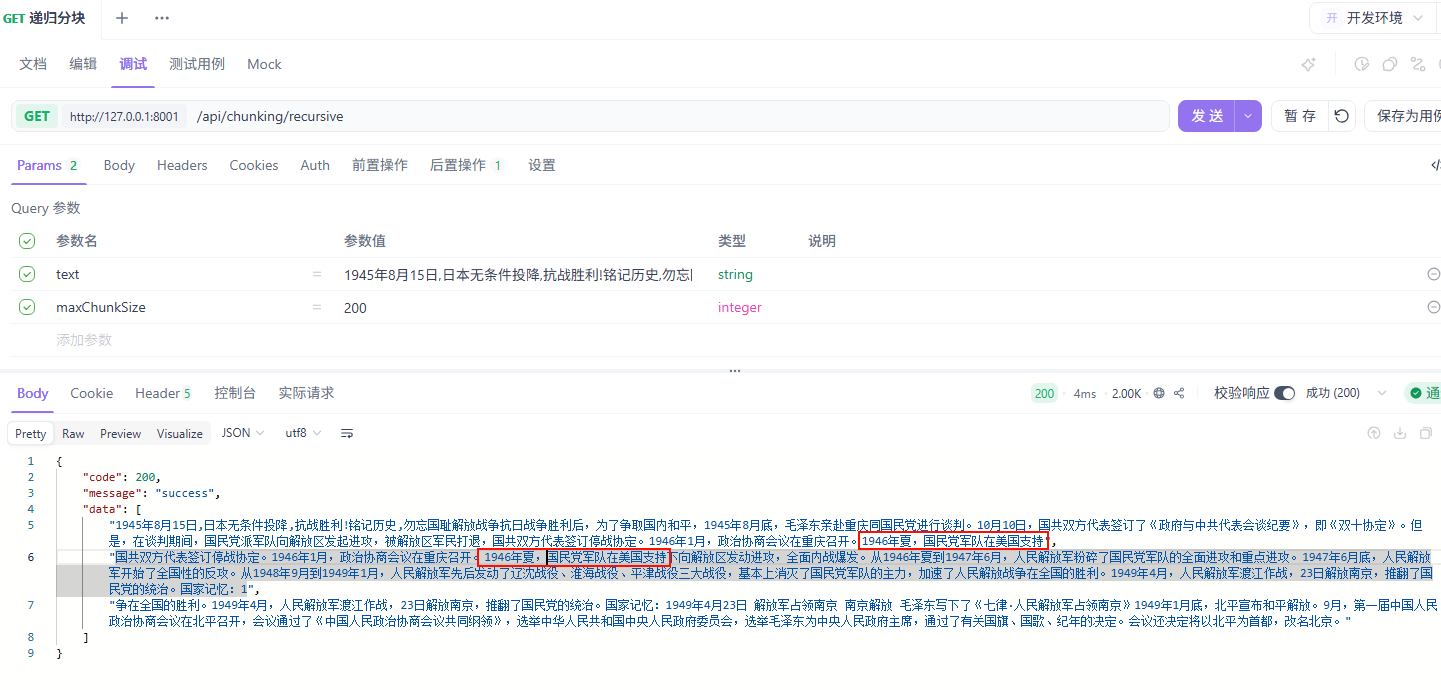
搭 RAG 系统,数据加载搞定了,下一步就是把文档切成小块。
这件事听起来简单,找个分词器按字数切就完了对吧?但真正做过的人都知道,分块策略选错了,后面检索怎么调都不对。召回的内容不是缺胳膊少腿,就是混入一堆不相关的东西,模型想答对都难。
我踩过这个坑。第一次做 RAG 的时候,觉得分块有什么好研究的,不就是切切切吗。结果上线一测,用户问”公司年假怎么算”,AI 召回的内容刚好从”年假”这个词中间切断了,答得驴唇不对马嘴。
从那以后我就知道了:分块这件事,值得认真对待。

文本分块(Text Chunking)就是把加载后的长文档切成更小、更易于处理的单元。每个小块,是后面向量检索和模型处理的基本单位。
你可能会问:为什么不直接把整篇文档向量化存进去?
有三个原因。
第一个,大模型有上下文窗口限制。 你的文档可能有 10 万字,但模型的上下文窗口可能是 128K tokens,直接塞进去会被截断,后面的内容模型根本看不到。
第二个,检索效率。 让 AI 在一整篇长文档里找几句关键信息,计算量巨大,响应慢,而且信息被稀释,答案不精准。切成小块之后,每个小块单独算向量,检索的时候直接在向量空间里做相似度搜索,快得多,精准得多。
第三个,上下文语义完整性。 糟糕的分块就像用尺子把”我喜欢吃苹果”机械切成”我喜欢吃苹”和”果”——AI 看了根本不知道在说什么。好的分块策略会遵循语义边界,确保每个块内部信息完整。
核心参数:chunkSize 和 overlap
动手切之前,有两个参数必须搞清楚:chunkSize(块大小)和 overlap(重叠量)。

chunkSize
chunkSize 就是每个块的长度上限。比如你设 chunkSize = 200,意思是每个块最多包含 200 个字符或者 200 个 token。
块太大,每个块包含的信息多,但检索时容易混入不相关的内容,精度下降。就像用户问退货政策,结果返回了一整章包含退货、换货、维修的内容,模型还得自己从里面挑。
块太小,每个块很精准,但可能把一个完整的意思切断了,上下文丢失。就像把一条退货规则从中间劈开,前半句和后半句单独看都不知道在说什么。
一般来说,200 到 1000 个字符是比较常见的范围,具体用多少,还是得根据你的文档类型和检索需求来反复调。
overlap
overlap 是指相邻两个块之间共享的文本长度。
打个比方:你在看一本小说,每次只能记住一页的内容。如果你严格按页翻,第 1 页看完翻到第 2 页,那第 1 页最后一句话和第 2 页第一句话之间的联系就断了。但如果你每次翻页时,把上一页最后几行重新看一遍,这几行就是重叠的部分,它帮你保持了上下文的连贯性。
用一个具体的例子来看。假设知识库里有这样一段退货政策:
自签收之日起 7 天内,商品未经使用且不影响二次销售的,消费者可申请七天无理由退货。生鲜食品、定制商品、贴身衣物等特殊品类不适用此规则,具体以商品详情页标注为准。
如果 chunkSize = 40,不加 overlap,切出来可能是:
- 块 1:自签收之日起 7 天内,商品未经使用且不影响二次销售的,消费者可申请七天
- 块 2:无理由退货。生鲜食品、定制商品、贴身衣物等特殊品类不适用此规则,具体
- 块 3:以商品详情页标注为准。
注意看,”七天无理由退货”这个关键词被切成了两半,分别落在块 1 和块 2 里。用户搜”七天无理由退货”,两个块都匹配不完整。
加上 overlap = 15 之后,切出来变成:
- 块 1:自签收之日起 7 天内,商品未经使用且不影响二次销售的,消费者可申请七天
- 块 2:消费者可申请七天无理由退货。生鲜食品、定制商品、贴身衣物等特殊品类不适
- 块 3:特殊品类不适用此规则,具体以商品详情页标注为准。
块 2 的开头和块 1 的结尾有重叠,”七天无理由退货”在块 2 里是完整的了。
当然,overlap 也不是越大越好。overlap 太大意味着大量重复文本,存储和计算成本都会上升。一般经验是 overlap 设为 chunkSize 的 10% 到 25%。
你可能注意到了,前面说 chunkSize 的时候,有时说字符,有时说 token。这两个东西不一样,有必要区分一下。
字符(Character)就是你肉眼看到的每一个符号。”你好”是 2 个字符,”Hello” 是 5 个字符,空格和标点也各算 1 个字符。
Token 是大模型实际处理文本的最小单位。大模型不是一个字一个字地读文本的,它会先把文本切成一个个 token。对于英文,一个常见单词通常是 1 个 token,长一点的单词可能被拆成 2-3 个 token。对于中文,一个汉字通常是 1-2 个 token。
为什么要关心这个?因为大模型的上下文窗口是按 token 算的,不是按字符算的。如果你用字符数来设 chunkSize,实际消耗的 token 数可能比你预期的多,尤其是中文场景。
不过在入门阶段,用字符数来设 chunkSize 完全够用。等你对 token 有了更深的理解,再考虑切换到基于 token 的分块也不迟。
分块策略
根据文档类型和任务选择合适策略是成功关键,以下是几种主流策略:
| 策略 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| 固定大小分块 | 按预设的字符数或 Token 数机械切分 | 简单、速度快 | 易破坏语义完整性 |
| 重叠分块 | 相邻块之间保留一定比例的重叠内容 | 减少边界信息丢失 | 存储成本增加 |
| 递归分块 | 按优先级顺序(段落→句子→空格→字符)递归切分 | 保留文档逻辑结构 | 实现稍复杂 |
| 语义分块 | 计算句子 Embedding 的相似度,在主题切换处切分 | 语义高度连贯 | 计算成本高 |
| 滑动窗口分块 | 通过滑动窗口创建重叠块 | 保持跨部分上下文连贯 | 冗余度高 |
| 模式特定分块 | 按内容类型分别处理 | 针对性强 | 实现复杂 |
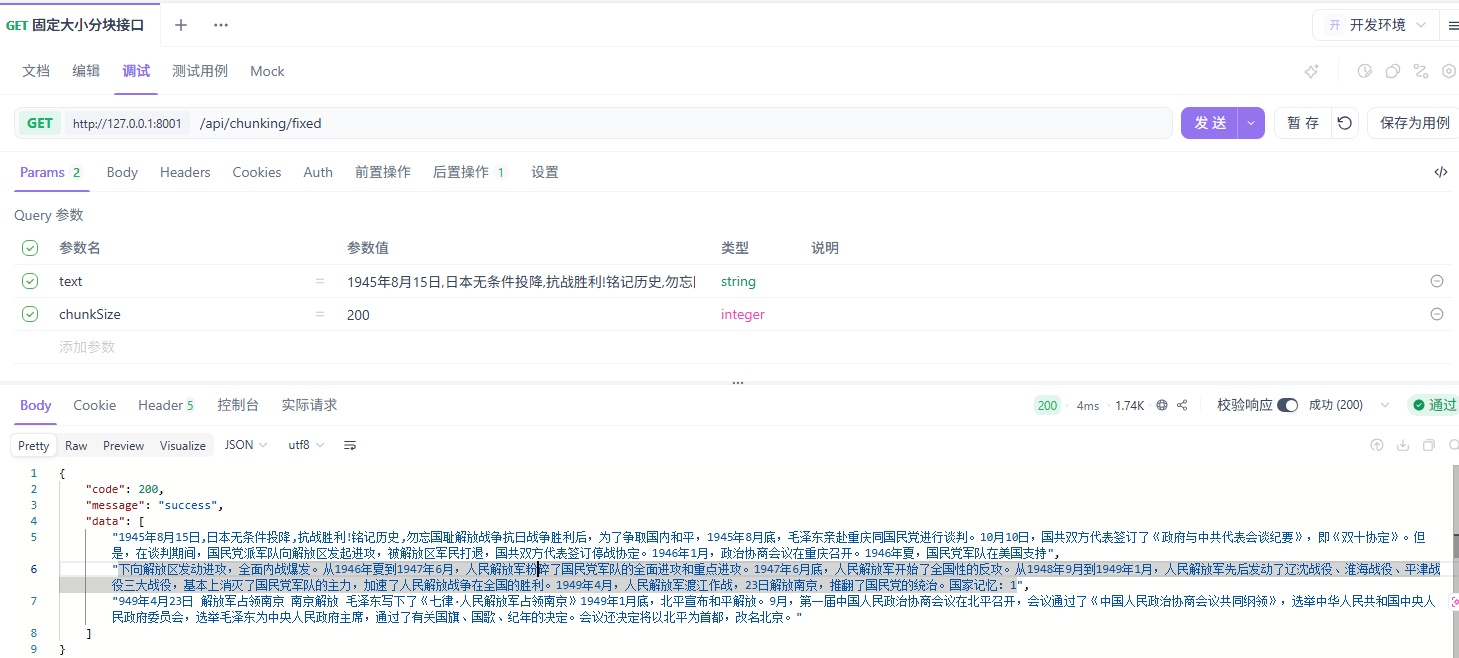
固定大小分块
最简单粗暴的策略。按预设的字符数或 token 数把文档机械切分,不管你这一刀切在段落中间还是句子中间,到了字数就切。
这既是它的优点,也是它的缺点。优点是实现极其简单,性能好,不需要任何 NLP 处理,调试起来也容易。缺点是忽略文本结构,容易把句子、段落从中间切断,导致语义不完整。
固定大小分块一般不用作主力策略,但经常作为保底方案——其他策略切完剩下太小的块,用固定大小来兜底。
执行结果:
重叠分块
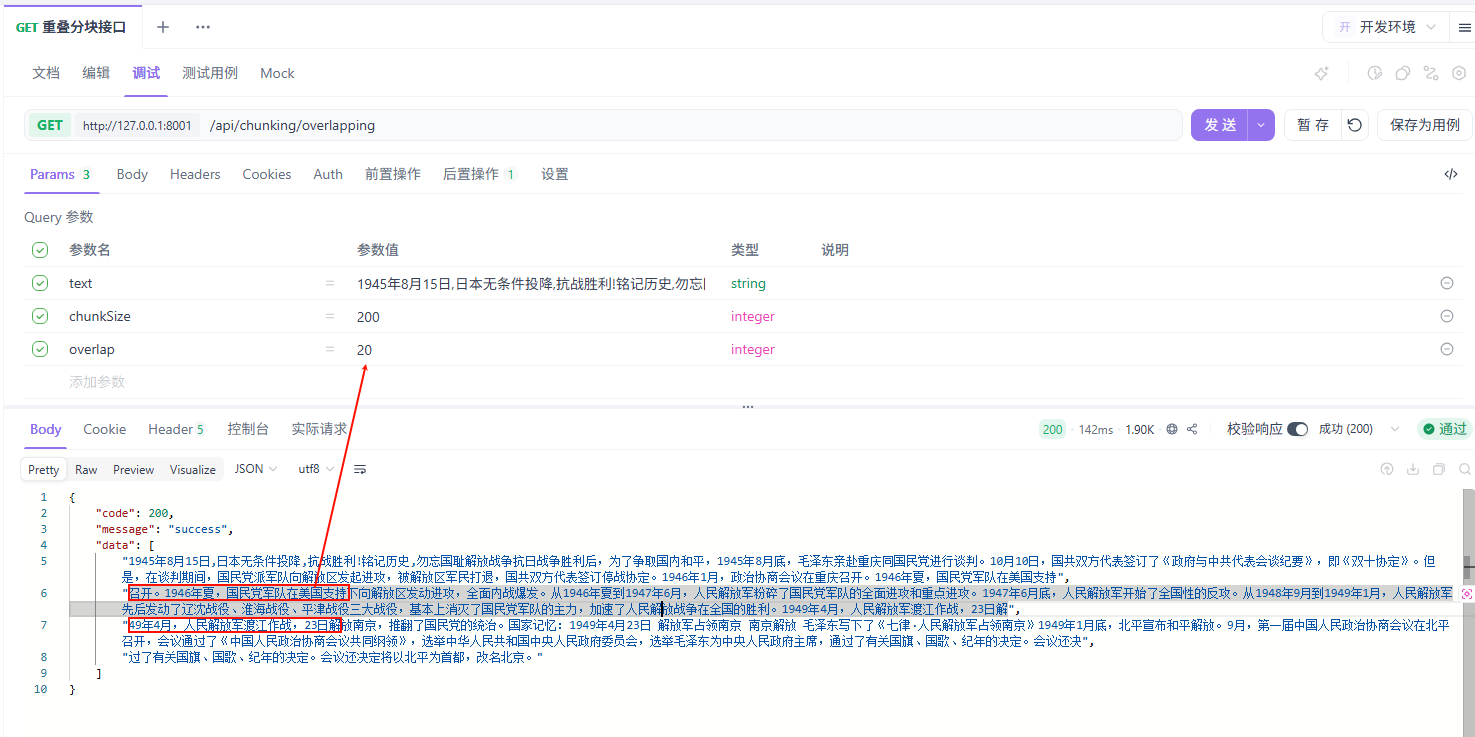
重叠分块是在固定大小分块的基础上,让相邻的块之间共享一部分内容。这种策略的核心目的是解决边界信息丢失的问题。
假设你设置 chunkSize = 500,overlap = 100,那么:
- 块 1:包含文档的第 1-500 个字符
- 块 2:包含文档的第 401-900 个字符(与块 1 重叠 100 个字符)
- 块 3:包含文档的第 801-1300 个字符(与块 2 重叠 100 个字符)
重叠分块也常用,尤其是法律文档和医疗文档这类上下文连续性要求高的场景。成本贵一点,但召回质量确实好。
执行结果:
递归分块
递归分块是目前实践中常用的策略。
它的思路一句话就能说清楚:先尝试用最大的分隔符切,切完如果某个块还是太大,就换一个更小的分隔符继续切,直到所有块都在 chunkSize 以内。
具体来说,它维护一个分隔符列表,按优先级从高到低排列:段落 → 句子 → 换行符 → 空格 → 字符。这个先粗后细的过程就是递归的含义——不是一刀切到底,而是逐层细化。
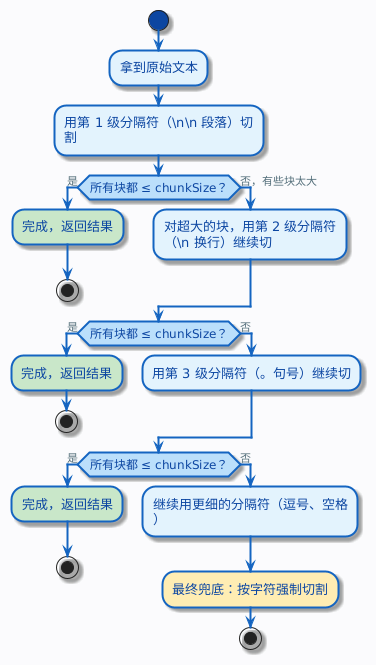
为什么这种方式好?因为它尽最大努力保留文本的结构。能按段落切就按段落切,段落太长了才按句子切,句子还太长才按逗号切……只有在万不得已的时候才会像固定大小分块那样按字符硬切。
如果你不知道该用什么策略,先用递归分块,不会错。基本都是先用递归分块跑通链路,看到具体问题之后,再根据文档特征换别的策略。
执行结果:
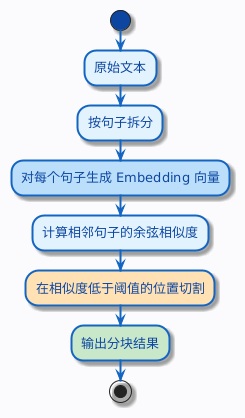
语义分块
前面几种策略有一个共同的局限:它们都是基于规则的——要么按字数切,要么按标点符号切。它们不理解文本在说什么。
语义分块换了一个完全不同的思路:用 Embedding 模型来判断文本的语义相似度,在语义发生明显变化的地方切割。
具体过程是这样的:
- 先把文本按句子拆开(这一步可以简单地按句号切)
- 对每个句子生成一个向量(Embedding)
- 计算相邻句子之间的向量相似度
- 当相邻句子的相似度低于某个阈值时,说明话题发生了转换,在这里切一刀
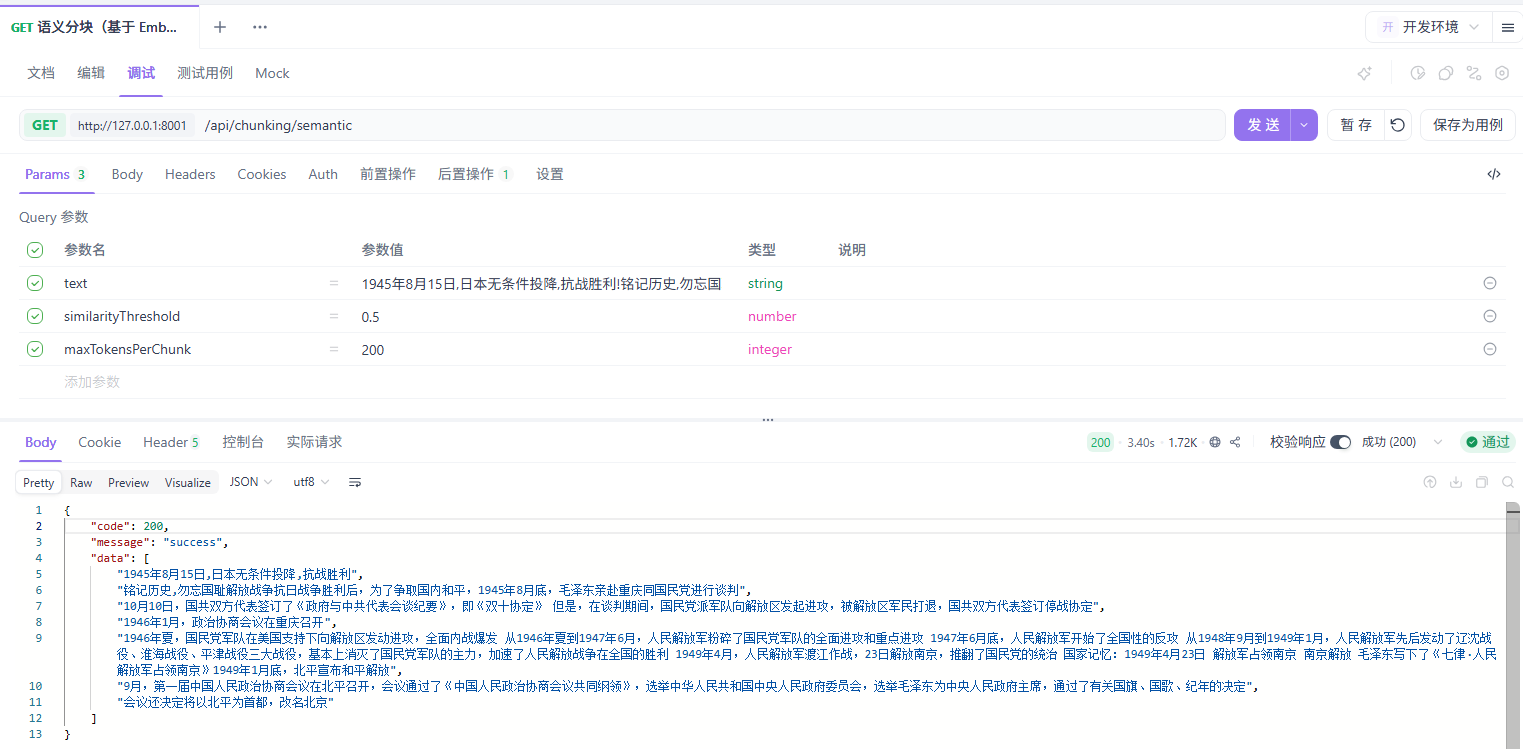
这种方式的好处是显而易见的:切出来的每个块在语义上是高度内聚的,不会出现一个块里混着两个不相关话题的情况。
语义分块效果好,但成本也高。我一般是在核心文档上用,辅助性的长尾文档还是用递归分块。
执行结果:
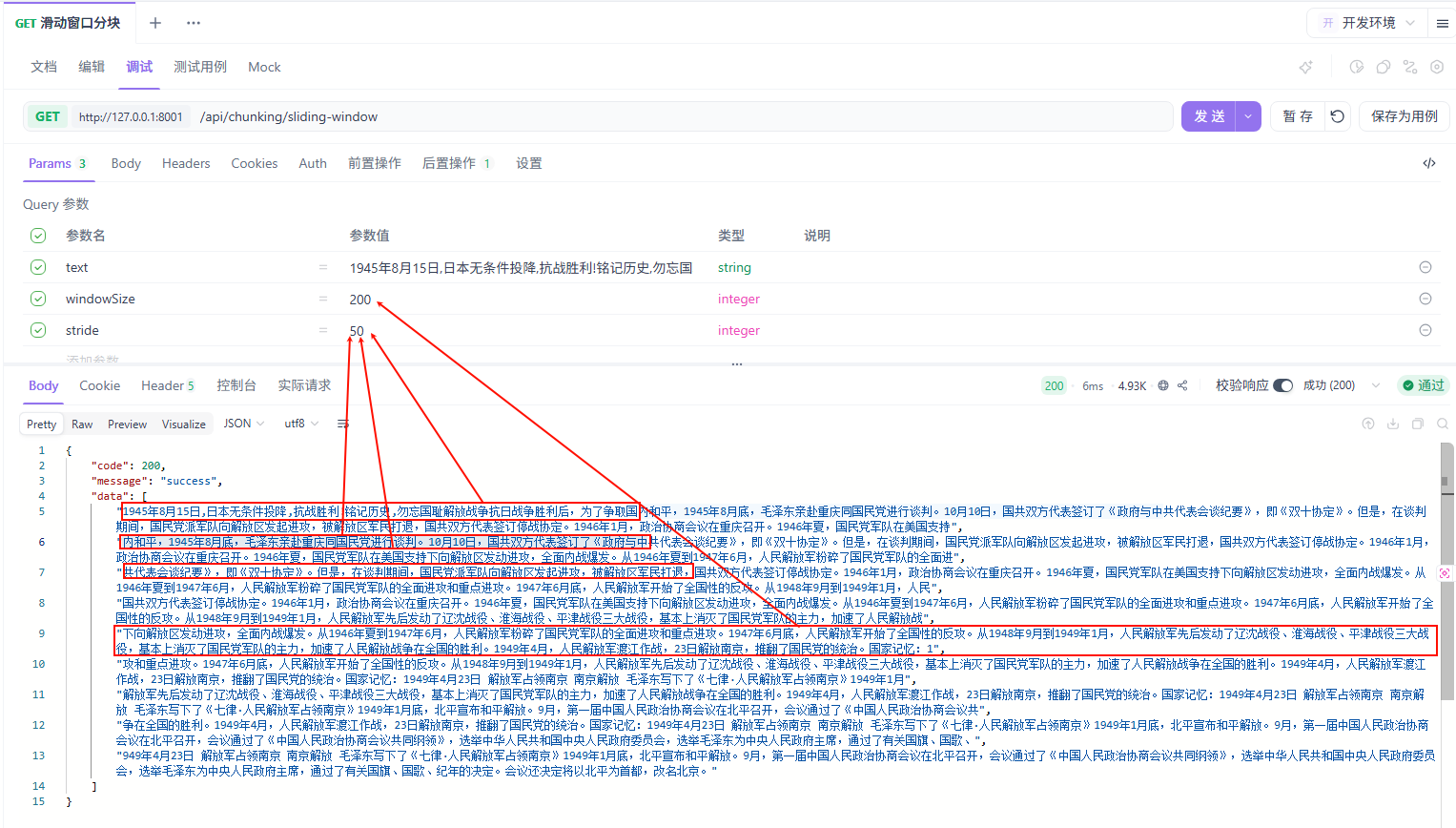
滑动窗口分块
滑动窗口分块是一种特殊的重叠分块策略,通过固定步长的滑动窗口来创建文本块。
滑动窗口分块有三个核心参数:
- window_size:窗口大小(每个块的长度)
- stride:步长(窗口每次滑动的距离)
- overlap = window_size - stride:重叠长度
滑动窗口分块我主要用在聊天记录和代码分析这类连续性要求高的场景,普通文档不太用。
执行结果:
模式特定分块
模式特定分块的核心思想是:不同类型的内容应该采用不同的分块策略。文本、表格、代码、图像各有其最佳的分块方式。
代码分块需要特别说一下。用普通文本分块处理代码会把函数从中间切断,正确做法是用 AST(抽象语法树)解析后按函数完整切分。
执行结果:
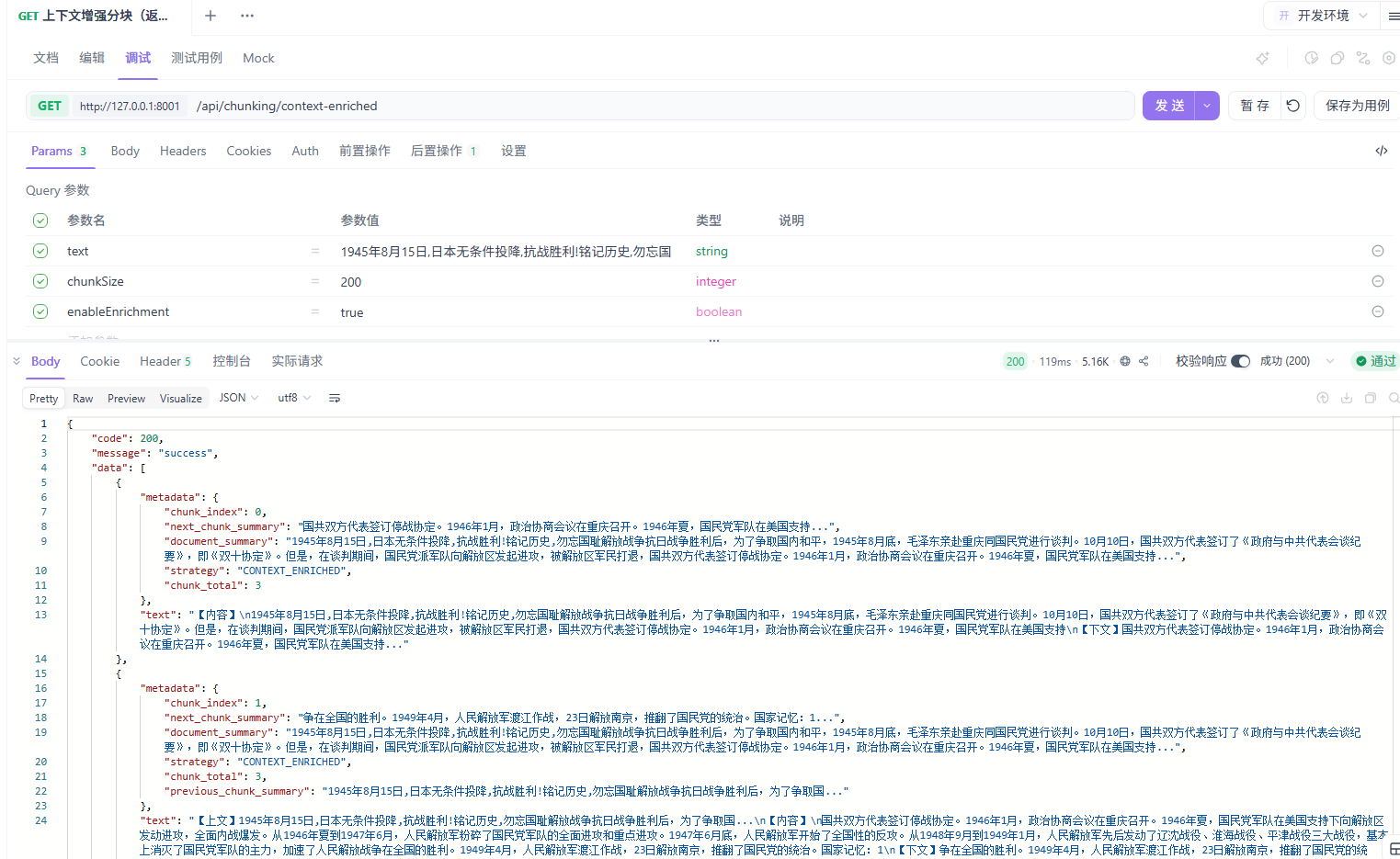
子文档分块
子文档分块是一种”分层摘要”策略。它先对整个文档或大章节生成摘要,然后将这些摘要作为元数据附加到各个子块上。这样每个子块都能”感知”到它所在的更大上下文。
执行结果:
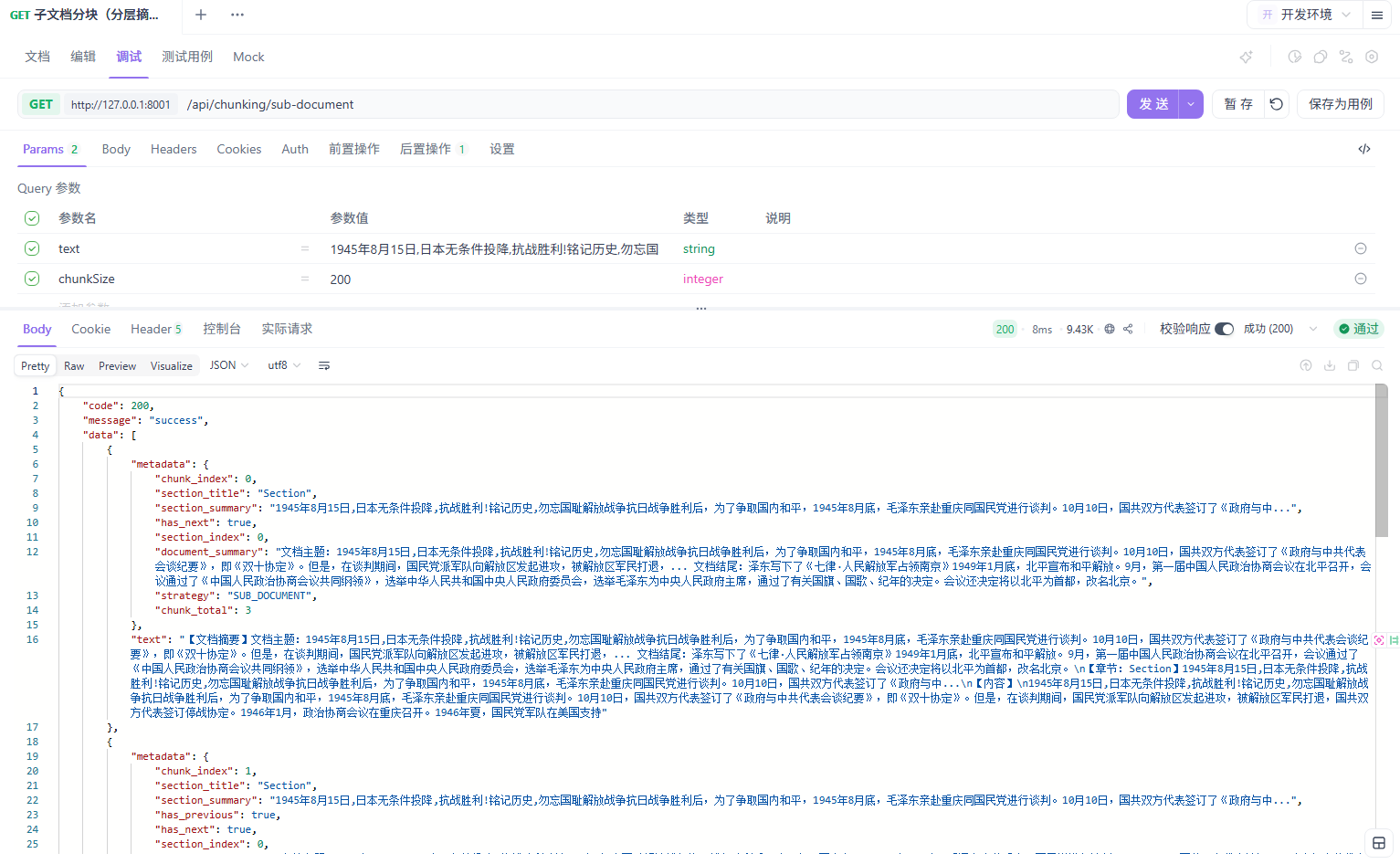
基于文档结构分块
基于文档结构分块利用文档自身的结构标记(标题、章节、页码、表格边界等)进行切分。这是一种”尊重原文”的分块策略。
我在 Markdown 文档上最喜欢用这种策略。Markdown 的标题结构天然就是分块边界,按 # ## ### 切,基本不会破坏语义。
执行结果:
智能体分块
智能体分块是一种由大语言模型动态决定如何切分的策略。它不依赖固定的规则,而是让模型”理解”文本后做出分块决策。
目前阶段这个策略更多是探索性的,生产环境用得还不多。但随着模型速度提升和成本下降,Agentic 分块可能成为主流。
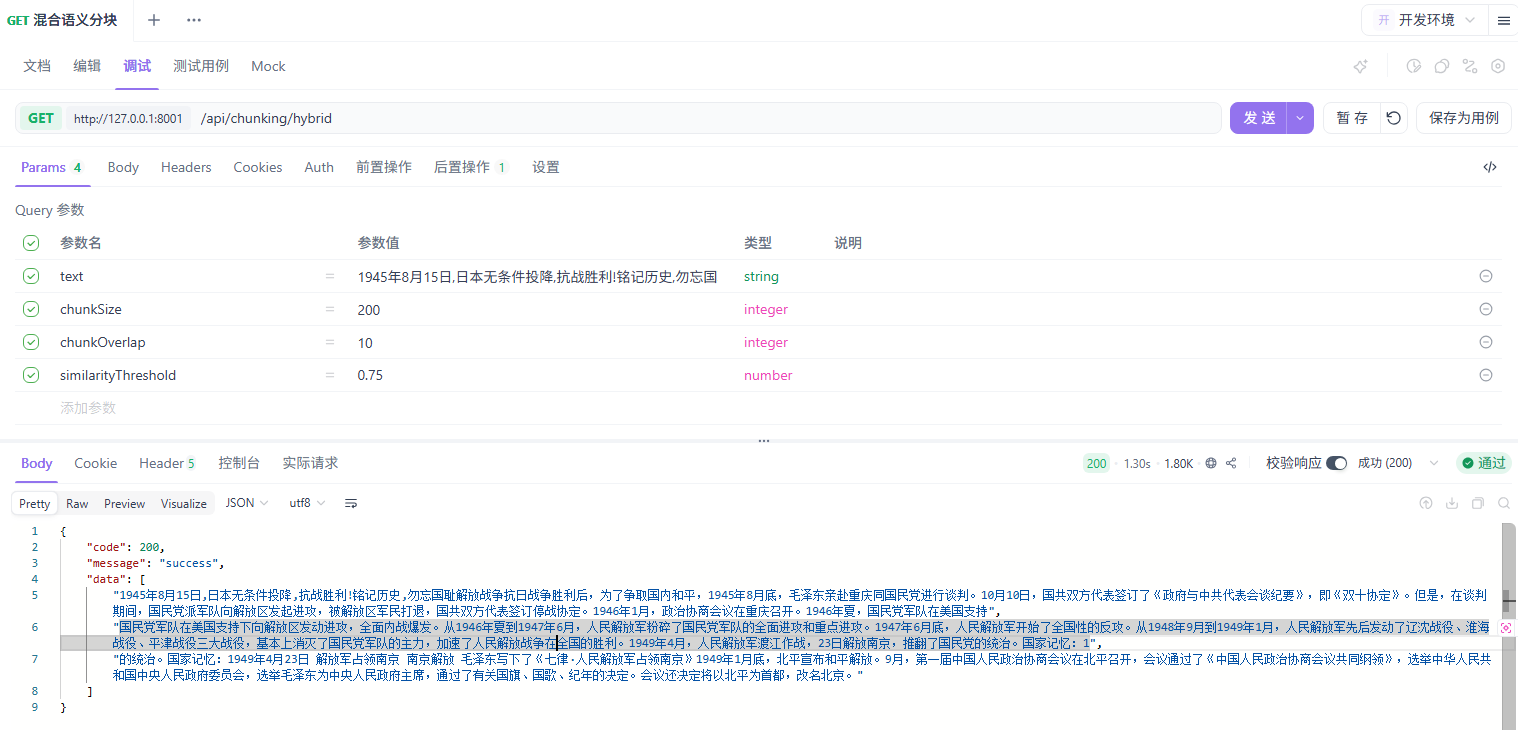
混合分块
混合分块是结合多种分块策略的”组合拳”。它旨在综合各种策略的优势,在效率、成本和质量之间取得平衡。
执行结果:
实战建议
分块这件事,没有一招鲜的万能策略。我自己的经验是:
先用递归分块跑通全链路。 这是最安全、最通用的默认选择,能 cover 住大多数场景。
根据文档类型选择基础策略。 Markdown 按标题切,代码按函数切,表格按行切,PDF 尽量先尝试按段落切。
overlap 不要省。 省这一点点存储成本,换来的是检索质量的提升,值。
块大小不是越小越好。 一般 500 到 1000 个 token 是比较舒服的区间。
元数据能抽就抽。 来源文档、页码、标题、版本号,这些信息在后面溯源和过滤的时候非常有用。
用真实问题来验证分块策略。 你设的参数好不好,不是你拍脑袋决定的,是用户问出问题来、系统答得对不对来验证的。
分块是 RAG 链路里看起来最不性感、但实际上影响最大的环节之一。模型选对了、Embedding 调好了、Prompt 设计得很完美——但分块切得不对,前面的努力全白费。这件事没有捷径,只能根据你的实际文档、实际用户问题反复调。
我的建议是:先跑起来,再调优。不要在一开始就追求完美的分块策略,先用递归分块让整个链路跑通,然后一步一步优化。这个顺序比什么都重要。
下一节我们来聊向量嵌入——文本是怎么变成数字的,以及 embedding 模型该怎么选。